Nội Dung
Trong thời đại hiện nay nhà nhà đề cập đến SEO nhưng bản chất hoạt động ra sao thì không phải ai cũng biết. Á Châu Media xin chia sẻ với các bạn những kiến thức nền tảng và trước hết là cách hoạt động của bộ máy tìm kiếm Google.
Cách bộ máy tìm kiếm hoạt động ra sao?
Các bộ phận của Google
- Thu thập dữ liệu ( Spider).
- Phân tích dữ liệu – lập chỉ mục.
- Mã hóa – thuật toán.
Spider (con bọ tìm kiếm của Google) Crawling & Indexing như thế nào?

Spider có thể
- Crawling (bò trườn) qua link trên các site đã index theo chỉ định của Meta name
- Crawling qua Add URL form
- Crawling qua Ip server reversed, DNS
- Crawling qua full domain search
Cơ chế tìm kiếm của Spider
Chúng ta theo dõi qua sơ đồ này để hiểu hơn.
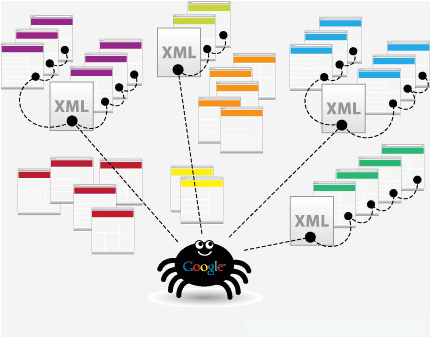
Đầu tiên nó lấy danh sách các máy chủ và trang web phổ biến. Spider sẽ bắt đầu tìm kiếm với một site nào đó, nó đánh chỉ mục các từ trên trang của nó và theo các liên kết ( link) tìm thấy bên trong Site này.
Theo phương pháp này, hệ thống tìm kiếm của Google sẽ nhanh chóng thực hiện công việc và trải rộng ra toàn bộ các phần được sử dụng rộng rãi nhất của web. Khi Spider xem xét các trang web ( định dạng HTML), nó lưu ý: Các từ bên trong trang web & Nơi nó tìm thấy các từ đó
Các từ xuất hiện trong các thẻ Title, Meta Description nó nhận định đó là phần quan trọng có liên quan đến sự tìm kiếm của người dùng sau này. Vì thế đối với mỗi website google nó sẽ có nhiều phương pháp để index lại chỉ mục, liệt kê lại các từ khóa chính. Nhưng dù dùng cách nào thì Google cũng luôn cố gắng làm cho hệ thống tìm kiếm diễn ra nhanh hơn để người dùng có thể tìm kiếm hiệu quả hơn hoặc cả hai.
Xem thêm: Dịch vụ viết bài content chuẩn seo chuyên nghiệp
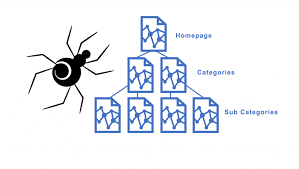
Kế đó Google sẽ xây dựng chỉ mục.
Sau khi nó tìm thông tin trên website nó sẽ nhận ra rằng nhiệm vụ tìm kiếm thông tin trên website sẽ không thể nào hoàn thành… bởi vì các QTV luôn thay đổi thông tin, cập nhật thông tin lên website và điều đó có nghĩa rằng Spider sẽ luôn thực hiện nhiệm vụ Crawling. Và chắc chắn rằng Google sẽ phải lưu các thông tin mà nó tìm được bằng một cách nào đó để có lợi nhất.
Sau đó nó sẽ mã hóa thông tin để lưu trữ dữ liệu trong CSDL đồ sộ của nó theo một thuật toán nào đó. Và dữ liệu này thì chắc chắn là rất bảo mật rồi. Rồi nó xây dựng chỉ mục để cho phép thông tin được tìm thấy một cách nhanh chóng.
Chúng có thể lấy ví dụ 1 cách như sau: Giả sử website của bạn làm về ngành du lịch… nó sẽ lưu các chỉ mục của website của bạn vào phần du lịch…Nếu site bạn làm về ca nhạc, nó sẽ lưu các chỉ mục web bạn vào phần ca nhạc…và như thế sẽ tránh được việc tìm kiếm bị chồng chéo lên nhau… vì ắt hẳn ai cũng biết rằng bộ máy tìm kiếm google có dữ liệu lớn tới mức nào.

Tóm lại
Chúng ta chỉ có thể can thiệp vào quy trình tìm kiếm của Google ở bước nó bắt đầu tìm kiếm và lên chỉ mục website. Còn về thuật toán cũng như hệ thống của Google thì thật khó để có thể can thiệp vào. Và cũng từ đây sản sinh ra 2 trường phái SEO: BlackHat SEO và WhiteHat SEO. Hãy đọc kỹ cách hoạt động của bộ máy tìm kiếm và lựa chọn những phương pháp viết SEO phù hợp và hiệu quả nhất nhé.