Nội Dung
Tôi đã viết một bài báo vào tháng 4 đề cập đến một số lập luận ủng hộ và phản đối việc chặn “bot AI” – tại thời điểm đó, đặc biệt là GPTbot và Google-Extended – và hậu quả tiềm ẩn của việc làm như vậy. Nếu nguồn cấp dữ liệu Twitter/X của tôi có bất kỳ thông tin nào, thì sự đồng thuận về việc chặn bot AI trong ngành SEO dường như rất phản đối nó, với tiền đề hợp lý là việc các thương hiệu xuất hiện trong các câu trả lời/đầu ra của Mô hình ngôn ngữ lớn (LLM) là hoặc sẽ trở nên quan trọng, giống như việc xuất hiện trong kết quả tìm kiếm của Google ngày nay là rất quan trọng.

Tuy nhiên, một phần rất đáng kể các trang web có thẩm quyền đang chọn chặn một hoặc nhiều bot AI. Điều này cũng có thể liên quan đến một số thương hiệu truyền thông lớn ký kết thỏa thuận với OpenAI – có lẽ coi việc loại trừ robots.txt là một phần đòn bẩy của họ. Ví dụ: Dotdash Meredith , Vox Media và The Atlantic , Financial Times , AP , Axel Springer và News Corp. Tôi đã nói trong bài báo tháng 4 rằng để hy vọng làm giảm tiềm năng của các đối thủ cạnh tranh do AI viết cho trang web của bạn, có lẽ bạn sẽ cần hành động tập thể hoặc hành động quần chúng đáng kể trong hầu hết các ngành dọc. Rõ ràng, phép tính cho thấy một số gã khổng lồ xuất bản này chiếm một phần khá lớn trong số nội dung có sẵn về một số chủ đề.
Cần phải đề cập đến ở đây rằng robots.txt không được thực thi theo bất kỳ luật nào. Đây là chuẩn mực của Internet và có chi phí công khai tiêu cực khi bỏ qua nó (tôi sẽ đề cập lại ngay sau đây), nhưng bạn phải đi xa hơn một chút so với dòng robots.txt để chặn hoàn toàn lưu lượng truy cập.
Bây giờ, tôi muốn xem xét kỹ hơn một chút về phạm vi mở rộng của các bot AI có thể chặn đã xuất hiện trong năm nay, cũng như ai đang chặn chúng và tại sao.
Dòng thời gian của bot AI: Những người mới đến
Chúng ta hãy cùng xem nhanh dòng thời gian:
-
2008 – Bắt đầu cuộc diễu hành chung
-
Ngày 7 tháng 8 năm 2023 – GPTBot (OpenAI)
-
Ngày 28 tháng 9 năm 2023 – Googlebot-Extended
-
Tháng 11 năm 2023 – Tài liệu đầu tiên được biết đến về PerplexityBot
-
Ngày 14 tháng 6 năm 2024 – Applebot-Extended
-
Tháng 6 năm 2024 – Những tranh cãi về PerplexityBot
-
Ngày 25 tháng 7 năm 2024 – OpenAI công bố nguyên mẫu SearchGPT, kèm theo OAI-SearchBot
Điều này không đầy đủ nhưng bao gồm một số sự kiện chính. Tôi không thể tìm thấy bất kỳ mốc thời gian cụ thể nào cho Anthropic, nhân vật chính mà tôi chưa đề cập đến trong mốc thời gian này.
Với OpenAI, Google và Apple, có vẻ như có một chiến lược là “thu thập mọi thứ chúng ta cần, sau đó công khai thông báo cách chặn thu thập dữ liệu”, điều này nghe có vẻ hơi giả tạo và chắc chắn củng cố cho lập luận rằng sẽ chẳng đạt được gì nhiều nếu chặn quá muộn trong quá trình đó.
Sự bối rối cũng khiến họ rơi vào tình trạng hỗn loạn về việc liệu họ có thực sự tôn trọng quy tắc robots.txt này hay không. Giả sử, họ đã thuê ngoài việc thu thập dữ liệu cho một bên thứ ba, bên này không làm vậy, và tất nhiên, robots.txt, như đã đề cập ở trên, không phải là luật mà là chuẩn mực chung của internet. Tuy nhiên, đối tác của họ tại AWS đã hơi khó chịu về điều này, cũng như nhiều báo chí công nghệ.
Dù sao đi nữa, không cần phải nói thêm nữa…
Phương pháp luận
Dữ liệu của tôi ở đây dựa trên kho dữ liệu MozCast gồm 10.000 thuật ngữ chính của Hoa Kỳ, được theo dõi từ một vị trí ngoại ô của Hoa Kỳ tại STAT. Tôi đã xem xét cả máy tính để bàn và thiết bị di động và mọi thứ hạng hữu cơ trong 20 vị trí xếp hạng hàng đầu, để lại cho tôi 341.553 vị trí xếp hạng từ 142.964 URL duy nhất trên 39.791 tên miền phụ duy nhất.
Sau đó, tôi kiểm tra xem robots.txt của từng tên miền phụ này có cho phép tôi thu thập thông tin trang chủ của chúng hay không, với 8 tác nhân người dùng khác nhau:
-
nhân loại-ai
-
Applebot-Mở rộng
-
Bytespider
-
CCBot
-
Google-Mở rộng
-
GPTBot
-
Bot phức tạp
-
Googlebot
Đáng chú ý là phương pháp này có thể bỏ sót các trang web sử dụng một trong những chiến thuật mà tôi đã đề xuất xem xét trong bài viết tháng 4 của mình – cụ thể là chỉ loại trừ một số phần trang web nhất định. Ở đây, để đơn giản, tôi chỉ kiểm tra các trang chủ, vì vậy tôi sẽ báo cáo thiếu tỷ lệ chặn khi xem xét các trang web chỉ chặn các phần cụ thể
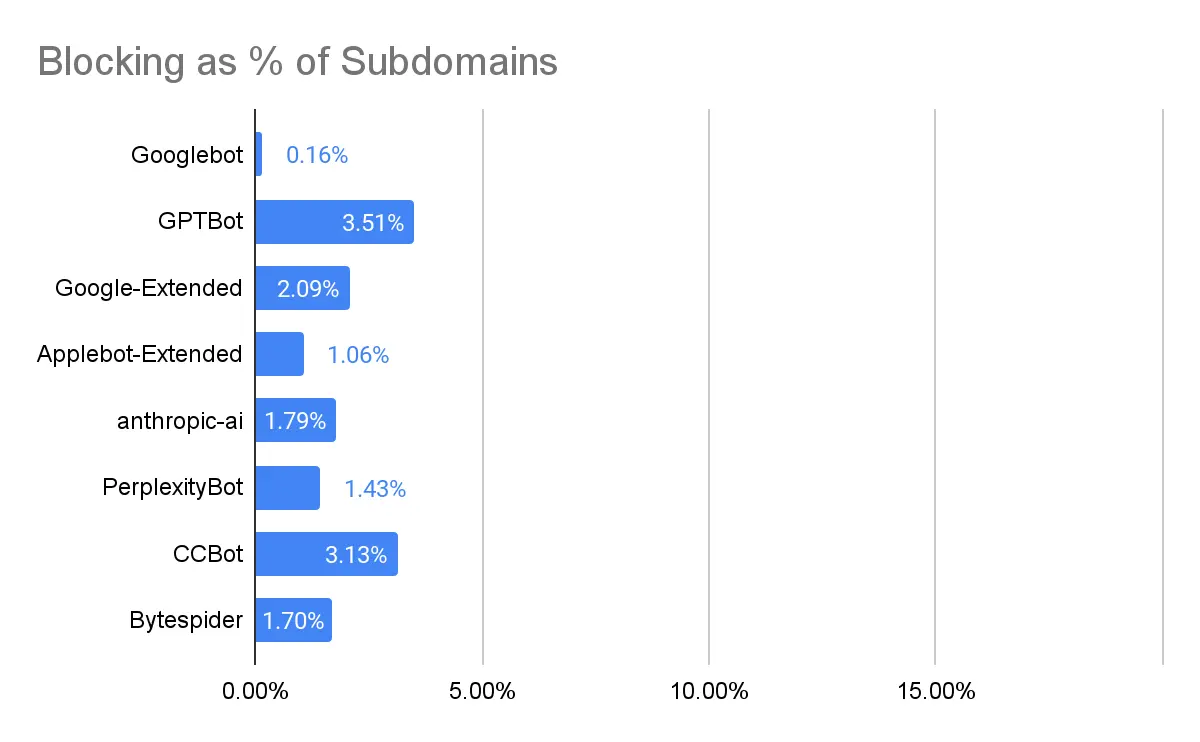
Tỷ lệ chặn
Trước tiên, hãy xem xét việc chặn theo % trong số 39.791 tên miền phụ đó. Tỷ lệ phần trăm thấp trên toàn bảng. Một số điểm chính cần lưu ý:
-
Thật thú vị, có những trường hợp các trang web chặn Googlebot nhưng vẫn xuất hiện trong các kết quả này. Một bài học hữu ích về sự khác biệt giữa thu thập dữ liệu và lập chỉ mục.
-
GPTBot là bot AI bị chặn nhiều nhất. Có khả năng là vì nó là một trong những bot đầu tiên và được thảo luận nhiều nhất.
-
CCBot, thật đáng thất vọng, cũng thường bị chặn. Tôi nói là đáng thất vọng vì đây là Common Crawl , một dự án công khai không phải chủ yếu là về việc đào tạo các mô hình AI. Ngoài ra, mặc dù chúng ta không thể nói khi nào các trang web này bắt đầu chặn CCBot nếu là gần đây, thì điều đó chắc chắn sẽ đóng cửa chuồng ngựa sau khi con ngựa đã chạy mất – các mô hình không còn nhận được thông tin mới nhất từ CCBot nữa.
Thật thú vị, bức tranh này trông khá khác biệt nếu chúng ta xem xét tỷ lệ phần trăm các URL xếp hạng đến từ các trang web bị chặn thay vì chỉ xem xét tỷ lệ phần trăm các trang web. Vì vậy, nói cách khác, chúng ta hiện đang cân nhắc các trang web có thứ hạng cao.
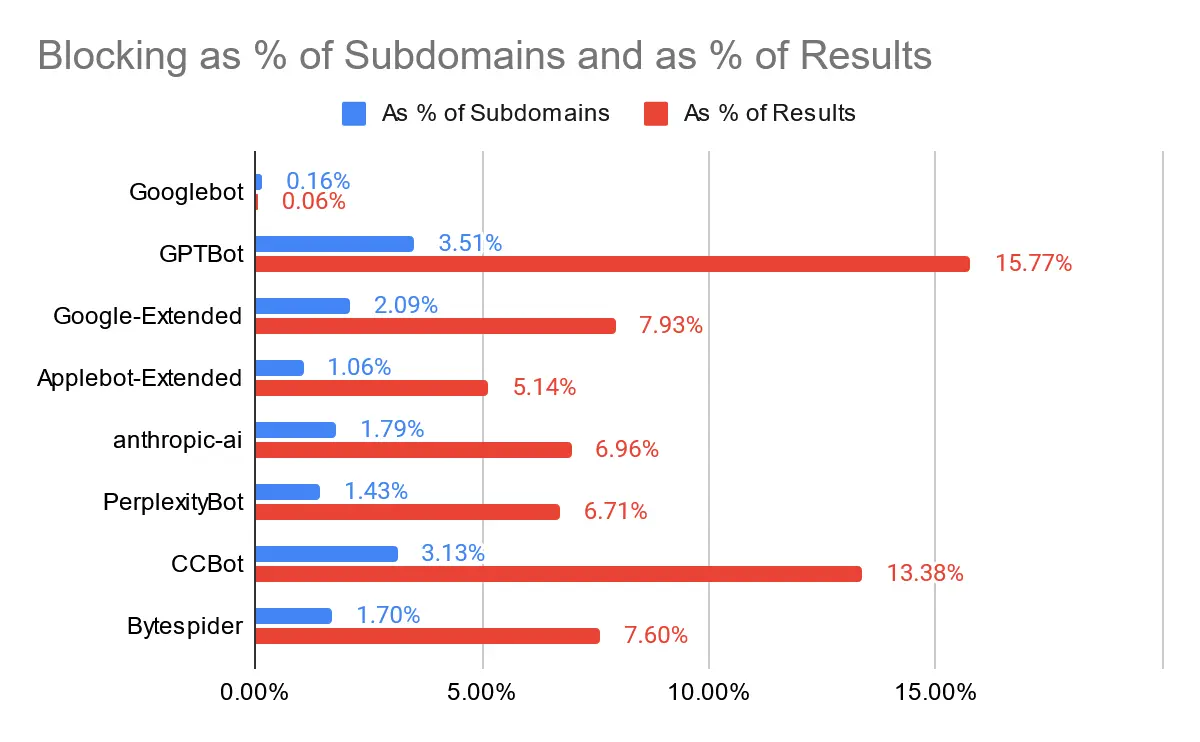
“Người chiến thắng” – nếu chúng ta có thể gọi như vậy – vẫn là GPTBot, và người về nhì vẫn là CCBot. Tuy nhiên, tỷ lệ phần trăm hiện đã lớn hơn đáng kể. Có thể 16% đang bước vào lãnh thổ “hành động tập thể” mà tôi đã nói đến trong bài đăng trước của mình không? Chắc chắn là không hề tầm thường.
Thực tế là tỷ lệ phần trăm kết quả chặn các bot này cao hơn nhiều so với tỷ lệ phần trăm tên miền phụ cho thấy các tên miền phụ có thứ hạng tốt và cho nhiều từ khóa có khả năng bị chặn không cân xứng. Điều đó phù hợp với lý lẽ “đòn bẩy” mà tôi đã đề cập trong phần giới thiệu của bài viết này. Chúng ta có thể thấy một hình ảnh tương tự nếu chúng ta phân đoạn theo Quyền hạn tên miền:
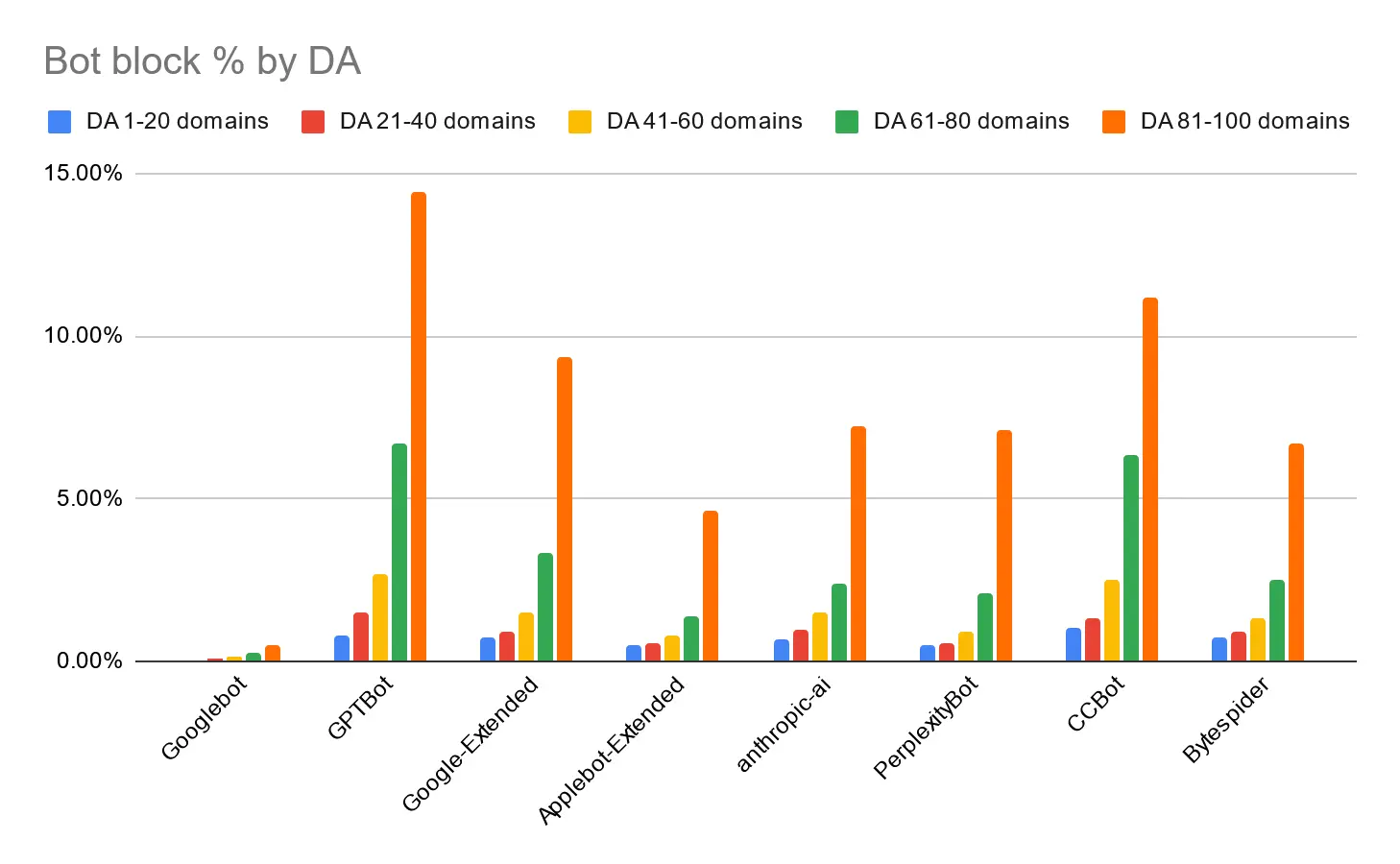
Các trang web có DA cao có nhiều khả năng chặn bất kỳ bot nào trong số này. Nếu bạn thắc mắc về các trang web có DA cao chặn Googlebot cũ thông thường, thì đó chủ yếu là các trang web của chính phủ hoặc ngân hàng, rõ ràng là thu thập được các tín hiệu mạnh đến mức Google thấy phù hợp để xếp hạng chúng mặc dù không thể thu thập nội dung.
Tại sao bạn hoặc bất kỳ ai nên chặn bot AI?
Tôi đã đề cập đến một số lập luận tiềm ẩn theo cả hai cách trong bài đăng trước của mình, nhưng sự thật là hiện tại khi xem xét lượng truy cập ít ỏi mà các mô hình này đang thúc đẩy, có lẽ nó không có tác động lớn trong ngắn hạn. Nếu bạn xem tệp robots.txt của Moz tại thời điểm viết bài, bạn có thể thấy chúng tôi chặn GPTBot khỏi trung tâm học tập và blog của mình – đây là một vị trí thỏa hiệp, nhưng cho đến nay chúng tôi chưa thực sự thấy bất kỳ lợi ích hay tác hại nào và chúng tôi cũng không mong đợi điều đó trong ngắn hạn. Tôi chắc chắn không nghĩ rằng việc so sánh với việc chặn Googlebot là công bằng – LLM chủ yếu là một công cụ tạo nội dung, không phải chủ yếu là một công cụ giới thiệu lưu lượng truy cập. Thật vậy, Google đã gợi ý rằng ngay cả Tổng quan AI của họ cũng không bị ảnh hưởng bởi Google-Extended, mà thay vào đó là Googlebot thông thường. Tương tự như vậy, tại thời điểm viết bài, OpenAI vừa công bố đối thủ cạnh tranh trực tiếp của Google là “SearchGPT” và cũng xác nhận rằng, giống như Google, nó đang thu thập dữ liệu bằng một tác nhân người dùng riêng biệt với các công cụ AI tạo ra khác – trong trường hợp này là “OAI-SearchBot”.
Điều tôi không đề cập trong bài viết đó là trường hợp của các nhà xuất bản lớn. Nếu bạn là một nhà xuất bản lớn và bạn nghĩ rằng mình có đòn bẩy và có thể đạt được thỏa thuận, bạn có thể muốn tạo ra tiền lệ – rằng các công cụ này không được phép truy cập miễn phí trừ khi chúng đạt được thỏa thuận chính thức. Ví dụ, công ty mẹ của The Verge, Vox Media, đã công khai tuyên bố rằng họ đã chặn quyền truy cập trước khi cuối cùng đạt được thỏa thuận. Tệp robots.txt trên theverge.com vẫn chặn rõ ràng hầu hết các bot AI khác, nhưng không phải (nữa) GPTbot.
Tất nhiên, phần lớn các trang web và phần lớn người đọc bài đăng trên blog này không phải là những nhà xuất bản lớn. Có thể việc bạn được nhắc đến trong nội dung do AI viết có giá trị hơn nhiều so với việc bạn cố gắng bảo vệ giá trị độc đáo của nội dung của mình, đặc biệt là trong một thị trường đông đúc các đối thủ cạnh tranh không có những lo lắng như vậy. Tuy nhiên, thật thú vị khi thấy những tiền lệ được thiết lập ở đây, và sẽ còn thú vị hơn nữa khi xem nó diễn ra như thế nào.
Đọc thêm: